Low-Code to No-Code: A Software Development Revolution
When software can almost write itself, then it's future proof.

Image Source: wabeno / iStock / Getty Images Plus via Getty Images.
Over the past 50 years, computer programming languages have made several significant advancements all focused on making a computer easier to use in a more human-readable format. If you wanted to learn programming in the early days you would have had to learn Assembly Language, a set of binary machine operation codes that instructed the microprocessor how to perform each step. This was extremely tedious work; something as simple as adding two numbers and storing the results could take as many as six steps, i.e. six operation codes.
Then computer engineers started creating compilers and function based programs that allowed for a more readable format, so a compiler could convert a function like “int sum(int a, int b)” into the operations codes required for the microprocessor. As the technology grew, more and more languages were created, each making programming easier yet still requiring a strict syntax required to instruct the compiler how to perform a specific task.
In the 1950s and ’60s, OOP (Object Oriented Programming) emerged further simplifying languages and programming tasks. OOP was very successful because it combined functions and data into a single object, allowing programmers to focus on the operations with even less knowledge of how the microprocessor carried out extremely complex operations under the hood.
Now we are witnessing the next evolution in software development: the “Low-Code to No-Code Revolution.” This is going to be a game-changer—even bigger than Object-Oriented Programming (OOP). Today novice programmers can create powerful applications with little to no knowledge of how microprocessors work. Simply express what you want the computer to do in a variety of formats and a tool will either write or help you write the code for you.
So, let me first explain the concept of Low-Code/No-Code by explaining what it is not. The overarching idea is to create working software without the overhead of thousands upon thousands of lines of code written by costly, high end software engineers. Software is expensive to write and maintain. The big picture idea of Low-Code/No-Code applications creates generic tools that enable non-programmers to tweak the functions and operations, saving time and money.
The concept of Low-Code/No-Code comes in several flavors. One of the best examples is a simple spreadsheet. You don’t have to be a computer programmer to create a spreadsheet containing a set of complex functions, calculations, and calculated results. If you have ever created a spreadsheet, you are in a sense writing a mini-computer program.
The elements of Object-Oriented Programming are apparent in a spreadsheet. You have both the data and the functions, both of which can be placed in a cell. There are a large number of functions available to the user/programmer, as well as VB Scripts for even more advanced tasks. And now Microsoft is adding LAMBDA expressions to Excel, giving the user even more programming power.
Another example of the Low-Code/No-Code is in many of the data access layers of an application. Programs need to Create, Read, Update, and Delete (CRUD) data from a database and to do that, most databases need a Standard Query Language (SQL) script to interact with the database. Though SQL is standardized, many databases have a slightly different format compared to a SQL statement. However, because CRUD operations are standardized, the software can auto-generate the SQL scripts that match database unique requirements. Developers don’t have to write specific SQL scripts for each database format, since the database driver builds the SQL automatically, on the fly, matching the unique format of the database.
This type of database/application programming has become the standard today. These auto-generated, built-on-the-fly SQL scripts come with a huge advantage: fields can be added and removed from the database or object code without the need to support and maintain the specific SQL scripts. Programmers today will write applications based on an Object-Relational Mapping (ORM) where all the SQL code will be written for them automatically. If they want to implement a no-SQL database, all they have to do is change the database driver. Everything is handled for them, with No-Code!
Another one of my favorite examples of Low-Code/No-Code programming is the idea of domain-specific languages that allow users to implement specific operations and tasks in software, usually with a graphical development environment. Generally, these tools will allow a user to define items and program execution in a flow-chart-like format, then the software will write the actual code from the flow-chart.
In this example from Wikipedia, the program tracks the coins inserted into the machine and checks if the amount is correct before dispensing the product and change (Figure 1). What is notable here is how much the program looks like an electrical schematic. The numbers you see are like readings the engineer would get if they were to probe the circuit. This makes the programming very intuitive for electrical engineers and probably why so many electrical engineers prefer this language.
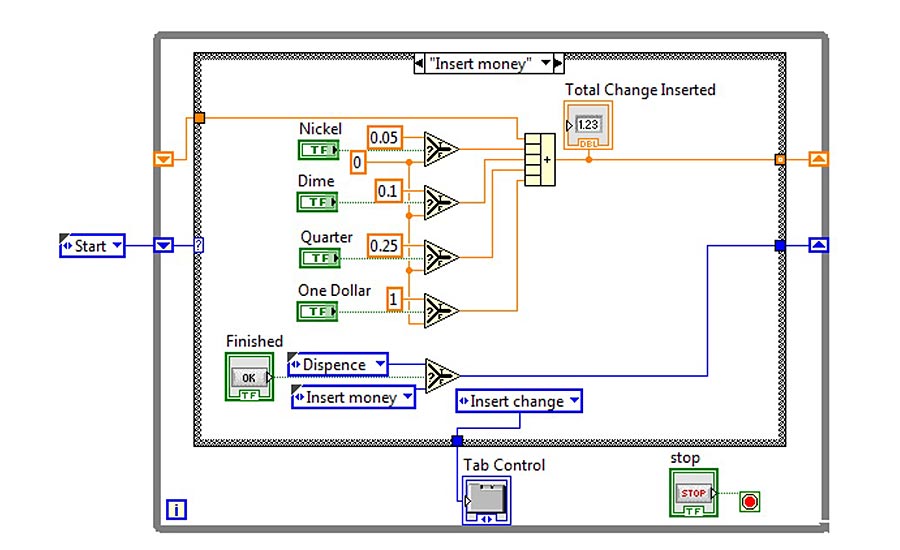
Figure 1: A LabView State Machine from Wikipedia’s vending machine sample coding [1].
Each of these examples have been around and on the market for decades--it is hardly revolution. But Low-Code/No-Code is not a syntactical change to software development; it is a focus shift from developers writing code to code writing code for developers.
Our goal was to approach metrology from a purely Object-Oriented perspective, defining all of the instrument settings and measurement process variables into name-value pairs. These name-value pairs could then be used to set up and configure the hardware during the measurement process.
More importantly, I wanted to code to be transportable to other languages and solutions. In the metrology world, hardware/lab standards last for 40+ years, while computer and programming technologies come and go. We needed to make software that is future proof; that is the advantage of Low-Code/No-Code software development. When software can almost write itself, then it’s future proof.
We started with fresh eyes looking at the problem from what developers call the 50 thousand foot view. There we could see metrology software is divided into three basic building blocks. First, there are the Test Points, what will be tested, and what are the pass/fails limits. Second, the instrument and test settings, how will the test be conducted and the Unit Under Test (UUT) Configured, and finally, how the UUT will be controlled.
The first two parts of the problem are easily contained in data and metadata. Data and metadata can be persisted in many formats. One of the best examples of data and metadata is an HTML document. In an HTML document, there is the content, paragraphs, tables, and other information of interest to the reader. Then there is the metadata, the data about the data. This is where the font information, paragraph layout, and other information are stored. The metadata tells the browser how to present the information to the reader.
For metrology, the data is the Test Points and Test Results, while the metadata is the UUT settings and test specifics for the test process. Figure 2 shows the metadata for a “TestProcess.Voltage.AC.Sinewave” metrology process. The metadata shows the required elements “Volts” & “Frequency” for the test process, as well as the UUT settings “Filter” & “Range” requirements for that Test Point.
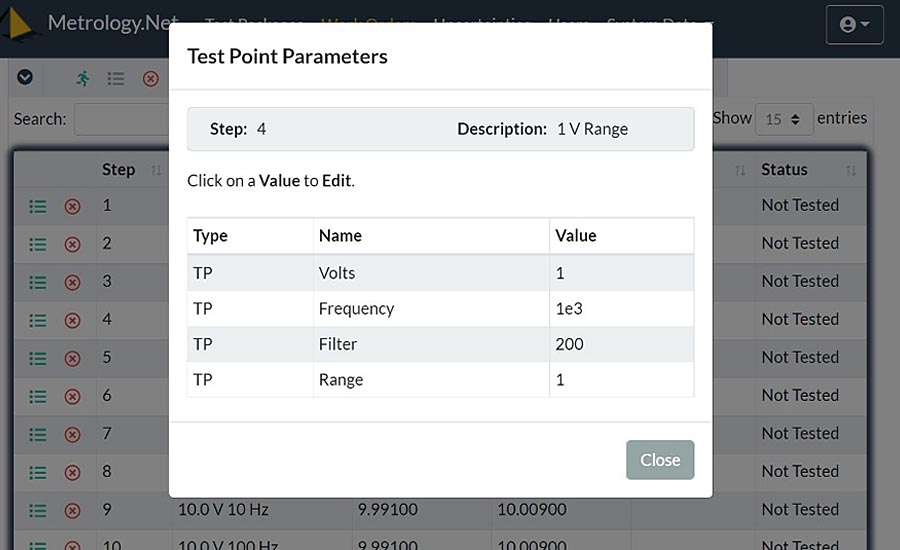
Figure 2: Metadata from a 1 Volt 1 kHz test point on a 34461A DMM.
What is important to note, is that we are only storing data about the test. Nothing has been defined or stored related to the specific hardware or software of measurement technique that will be used. The only thing specifically stated is the “TestProcess.Voltage.AC.Sinewave,” shown in Figure 3, and the test points to be tested, each with their specific metadata.
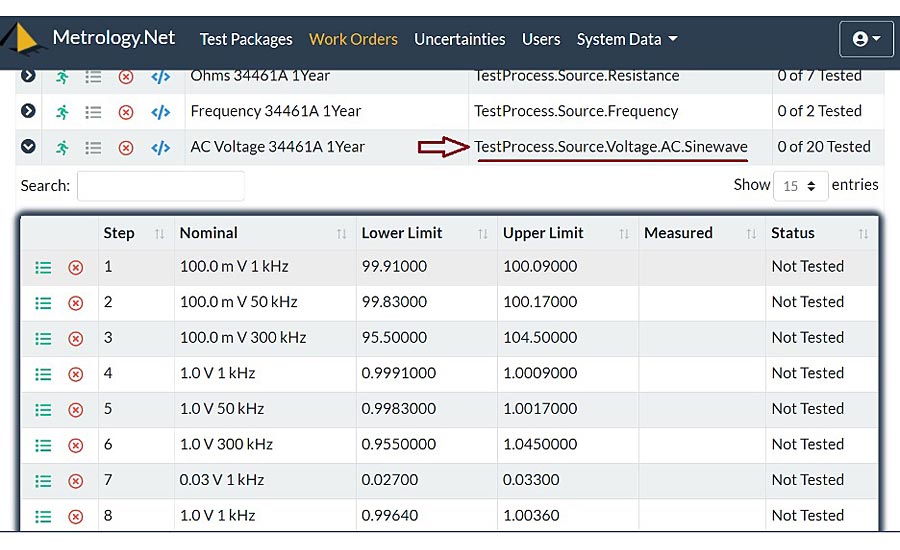
Figure 3: Test Points from a 34461A calibration.
The last element in our model is the control script for the UUT using VISA Commands. Here we are showing an example of metrology bocks, a modified version of Google Blocks customized specifically for instrument control. As seen in Figure 4, the user is able to organize the block on the left-hand side of the screen while the code is generated on the right side.
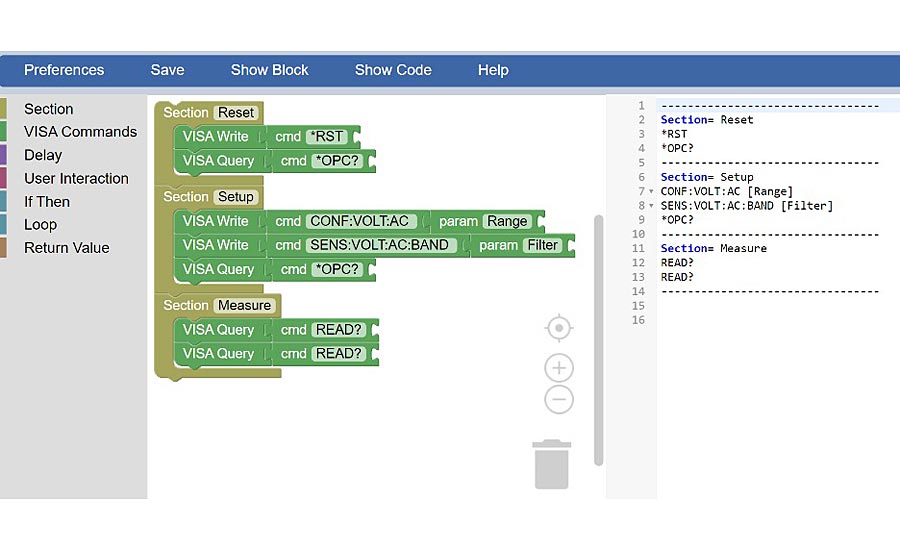
Figure 4: AC Voltage commands for a 34461A.
In Figure 4, you can see that there are only three sections: “Reset”, “Setup”, and “Measure”. This is because the “TestProccess.Source.Voltage.AC.Sinewave'' only needs those three calls to the UUT’s control script.
At first, this all seems confusing, a little backwards from all programs test scripts that run from start to finish. But the Low-Code/No-Code concept is all about programs writing programs--building blocks that fit together--so you have to think backwards.
In metrology, the test point definition and metadata and UUT driver is all that is needed. Like in the SQL example, the items are dynamically bound at runtime and the drivers simply run the calibration without the need of maintaining specific scripts for every reference standard. Alternatively, the tests can be pushed to a stand-alone Windows application, even exported to a spreadsheet for manual calibrations.
It will take a little bit of time for users and programmers to wrap their heads around Low-Code to No-Code software development. But if you think about it like this, the three elements--data, metadata, and control scripts--are timeless. They will always be the same for a given UUT. Add in a Low-Code solution and the software writes most of itself. Upgrade it to a No-Code solution and nothing needs to be written; it just works! Q
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!





