Measurement
Beyond DMAIC: Leveraging AI and Quality 4.0 for Manufacturing Innovation in the Fourth Industrial Revolution
Effective AI deployment requires addressing challenges related to continuous learning, adaptation, and the robust management of vast, real-time data streams—areas where DMAIC falls short.

Image Source: putilich / iStock / Getty Images Plus
Quality 4.0 represents the next phase in the evolution of quality management, integrating cutting-edge technologies such as artificial intelligence (AI), cloud storage and computing (CSC), the Industrial Internet of Things (IIoT), and big data. Unlike traditional frameworks that focus on incremental improvements, Quality 4.0 harnesses AI to drive transformative innovations in manufacturing, making it particularly effective in managing the complexities and scale of modern production processes.
As manufacturing evolves, the role of AI becomes increasingly pivotal. However, traditional methodologies like Six Sigma’s DMAIC (Define, Measure, Analyze, Improve, Control) framework may not be sufficient to guide the development and implementation of AI solutions. Effective AI deployment requires addressing challenges related to continuous learning, adaptation, and the robust management of vast, real-time data streams—areas where DMAIC falls short.
This article explores the evolution of manufacturing data across industrial revolutions, examines the limitations of DMAIC in the context of the Fourth Industrial Revolution, and introduces Binary Classification of Quality (BCoQ) and Learning Quality Control (LQC) systems as key components of the Quality 4.0 initiative. Additionally, I propose a five-step problem-solving approach, grounded in both theory and practical experience, to guide the successful development and implementation of LQC systems in today’s dynamic manufacturing environments.
The data
The volume and nature of manufacturing data has evolved along with the industrial revolutions. A chronology of this evolution and examples of the relevant data for the LQC systems is presented.
The evolution
The evolution of manufacturing data has mirrored the broader technological advancements across the industrial revolutions, each phase bringing new types of data and challenges in quality control.
First Industrial Revolution (Late 18th to Early 19th Century):
Technological evolution: The shift from manual labor to mechanized production powered by water and steam marked this era.
Data characteristics: Data during this time were primarily qualitative, recorded manually on paper, with quantitative data limited to basic financial records and simple counts.
Second Industrial Revolution (Late 19th to Early 20th Century):
Technological evolution: The advent of mass production and assembly lines revolutionized manufacturing processes.
Data characteristics: The introduction of paper-based tracking systems, such as cards and charts, enabled more systematic production, inventory, and quality control. While data generation increased, it remained largely manual and confined to physical records.
Third Industrial Revolution (Mid-20th to Late 20th Century):
Technological evolution: The rise of electronics and information technology introduced automation in manufacturing, with computers and robotics playing a significant role.
Data characteristics: The digital era began, characterized by the use of Material Requirements Planning (MRP) and Enterprise Resource Planning (ERP) systems, along with Computer-Aided Design (CAD) and Computer-Aided Manufacturing (CAM). This period saw an explosion in data generation, transitioning from megabytes to gigabytes, yet it was only a precursor to the data volumes seen in the Fourth Industrial Revolution.
Fourth Industrial Revolution (21st Century Onward):
Technological evolution: The integration of smart factories, IIoT, Cyber-Physical Systems (CPS), AI, and big data defines this era.
Data characteristics: Modern manufacturing now generates massive amounts of real-time data, primarily from sensors and IIoT devices. This data supports real-time monitoring, predictive maintenance, and process optimization. The shift from structured to unstructured data, including images, audio, and sensor readings, has necessitated more advanced data management, storage, and analysis solutions. Today, manufacturing data is measured in terabytes to yottabytes, emphasizing the need for sophisticated technologies to handle the vast volumes and variety of data generated.
Throughout these industrial revolutions, the nature of manufacturing data has evolved from limited, mostly qualitative information to vast quantities of unstructured, quantitative data. This exponential growth in data necessitates advanced solutions for data management, storage, and analysis, positioning Manufacturing Big Data (MBD) as a crucial element in modern manufacturing.
Manufacturing big data
MBD refers to a large amount of diverse time series generated by manufacturing systems. With the help of data and AI technologies, the intelligence of Smart Manufacturing (SM) systems can be enhanced. However, only a few companies are using MBD even though leaders have made significant efforts to generate value. For example, an oil and gas company discards 99% of its data before decision-makers can use them. According to a global research survey of more than 1,300 respondents conducted by Splunk, around 60% of the data remains dark, that is, unanalyzed, unorganized, and unrecognized, as reported by global managers and leaders in both business and IT. Several other surveys also revealed that up to 73% of company data is unused. One of the main reasons is that unstructured data is growing exponentially, which poses a significant challenge for manufacturing companies. According to a survey, 95% of companies believe that their inability to understand, manage and analyze unstructured data prevents them from driving innovations. Although there are many potential applications for MBD, this article will focus on developing and understanding Binary Classification of Quality (BCoQ) datasets, which are the foundation of LQC systems.
Binary classification of quality data sets
BCoQ data sets are process-derived data that are used to train Machine Learning (ML) or Deep Learning (DL) algorithms to develop a binary classifier. This classifier is then deployed to production to predict or detect defects. Each sample in the data set can have two potential outcomes, namely good or defective. The classification notation (Eq. 1) is used to assign labels. A positive label refers to a defective item, while a negative label refers to a good-quality item.

Manufacturing industries commonly deal with unstructured data in the form of signals or images. The welding process, for example, generates power signals which are shown in Figure 1. The use of DL techniques has allowed us to develop AI-based vision systems for quality control, an important research area in Q4.0. These systems can reduce or eliminate human-based monitoring systems. Figure 2 illustrates a data set designed to detect misalignments in car body parts. Figure 3 and Figure 4 show potential applications of DL for quality control and automation. The first figure displays a data set that helps detect missing important components, such as a tire, and the second figure illustrates an application that aims to detect a common defect.

Figure 1: Signal from a power sensor (low resolution).
|


Figure 4: A learning data set aimed at detecting a common defect.
|

Table 1: A learning data set based on features derived from a signal.
|
Table 2: A learning data set based on process measurements.
|
Table 3: A learning data set based on deviations from nominal.
|
Figure 5: Target and observed position. Deviations in a 3D space (x,y,z).
|Traditional ML algorithms, such as support vector machines, logistic regression, or classification trees, learn quality patterns from structured data. Typically, structured BCoQ datasets are created by a combination of the following:
- Feature engineering techniques (extraction or discovery), e.g., statistical moments derived from signals (Table 1).
- Single measurements, such as pressure, speed and humidity (Table 2).
- Deviations from nominal (Table 3, Fig.5).
The limitations of DMAIC in the context of manufacturing innovation
The DMAIC methodology, while effective for improving processes within a relatively stable environment, is primarily designed around a linear and structured approach to problem-solving. It relies heavily on human expertise, statistical tools, and the assumption that processes are well-understood and can be measured and controlled with traditional methods. However, the rise of Industry 4.0 technologies has introduced new complexities that challenge the effectiveness of DMAIC in several ways:
- Complexity and non-linearity in manufacturing processes:
- Traditional Six Sigma methods like DMAIC work well when dealing with linear and predictable processes. However, modern smart manufacturing involves highly complex, nonlinear systems that operate in hyperdimensional spaces. These processes exhibit transient sources of variation, reduced lifetimes of solutions, and non-Gaussian behaviors that are not easily captured by the DMAIC methodology. For example, traditional quality control techniques are inadequate for handling the high-dimensional feature spaces and dynamic variations seen in smart manufacturing.
- Data-driven vs. hypothesis-driven approaches:
- DMAIC is fundamentally hypothesis-driven, meaning that it starts with a defined problem and uses statistical methods to test hypotheses and identify solutions. This approach can be limited in environments where the data is too complex for humans to fully comprehend without the aid of advanced computational tools. AI, particularly ML, shifts the paradigm towards a data-driven approach, where the system learns from vast amounts of data without the need for predefined hypotheses. AI excels in identifying patterns and making predictions in scenarios where the underlying processes are not fully understood, something that DMAIC is not equipped to handle.
- Adaptability and continuous learning:
- AI systems, especially those involving ML, can continuously learn from new data and adapt to changes in the manufacturing process. This adaptability is crucial in Industry 4.0, where innovation drives rapid changes and the process itself is constantly evolving. In contrast, DMAIC is a static methodology that requires reapplication whenever the process changes significantly, which can be time-consuming and inefficient. In Industry 4.0, solutions must be designed with auto-execution capabilities, where the code can automatically learn and adapt to new patterns as the system is exposed to new sources of variation. This auto-execution ensures that the system remains effective and up to date without requiring manual intervention every time the process shifts, thus maintaining efficiency and responsiveness in a dynamic environment.
- Handling big data and the infrastructure required:
- The vast amounts of data generated in modern manufacturing environments (industrial big data) present significant challenges that DMAIC is ill-equipped to address. AI techniques are specifically designed to handle big data, extracting valuable insights from large datasets that would overwhelm traditional Six Sigma methods. However, effectively leveraging AI in this context requires robust infrastructure capable of generating and processing real-time data.
- Real-time data generation: To monitor and optimize manufacturing processes effectively, it is essential to establish a robust infrastructure that can generate and collect real-time data. This involves deploying sensors, IoT devices, and advanced monitoring systems across the manufacturing environment. The Industrial Internet of Things (IIoT) plays a critical role in this setup, enabling seamless communication between devices and systems, thereby creating a comprehensive network of interconnected data sources.
- Cloud storage and computing: Handling the immense volumes of data generated by these systems necessitates advanced storage solutions. Cloud storage and computing provide scalable and flexible platforms to store and analyze this data. These platforms enable manufacturers to manage large datasets without the need for extensive on-premises infrastructure, allowing for real-time analytics and decision-making capabilities.
- Deployment technologies - fog and edge computing: While cloud computing offers vast storage and processing capabilities, the latency associated with sending data to and from centralized cloud servers can be a bottleneck in real-time applications. Fog and edge computing address this challenge by bringing data processing closer to the source of data generation. Edge computing allows data to be processed at the device level or near the data source, reducing latency and enabling faster responses to manufacturing anomalies. Fog computing extends this concept by providing a distributed computing architecture that processes data within the local network, further enhancing the ability to handle time-sensitive data and support real-time decision-making.
- Integration with AI: The combination of AI with these advanced computing infrastructures enables manufacturers to not only store and process vast amounts of data but also to derive actionable insights in real-time. This integration is crucial for maintaining high levels of quality and efficiency in today’s competitive manufacturing landscape, where decisions must be made quickly and accurately to respond to dynamic conditions.
- The vast amounts of data generated in modern manufacturing environments (industrial big data) present significant challenges that DMAIC is ill-equipped to address. AI techniques are specifically designed to handle big data, extracting valuable insights from large datasets that would overwhelm traditional Six Sigma methods. However, effectively leveraging AI in this context requires robust infrastructure capable of generating and processing real-time data.
While the DMAIC methodology of Six Sigma has served well in the past, its limitations become apparent in the face of the complexities introduced by modern smart manufacturing. Six Sigma is traditionally designed to analyze structured or tabular data, where rows represent samples and columns represent features. This method is well-suited for dealing with data sets that are quantitative, well-defined, and manageable using conventional statistical tools. However, as manufacturing has evolved, especially in the context of the Fourth Industrial Revolution, the nature of data has drastically changed.
Modern manufacturing systems now generate vast amounts of unstructured data—such as images, audio, video, and sensor readings—that do not fit neatly into tables. Six Sigma methodologies struggle to handle this type of data effectively because they rely on traditional statistical approaches that require data to be in a structured format. This limitation becomes a significant barrier in today’s manufacturing environment, where unstructured data holds crucial insights for real-time monitoring, predictive maintenance, and quality control.
In contrast, the Fourth Industrial Revolution has ushered in a new era where the ability to process and analyze unstructured data is paramount. The integration of AI and Quality 4.0 has provided new tools and methodologies capable of handling the dynamic, nonlinear, and data-intensive nature of contemporary manufacturing processes. AI-driven approaches can analyze vast amounts of unstructured data, extracting patterns and insights that traditional Six Sigma methods would overlook. For example, DL algorithms can process images from quality control systems to detect defects with greater accuracy and speed than human operators or traditional statistical methods.
By moving beyond DMAIC and embracing AI-driven approaches, supported by robust infrastructure like cloud, fog, and edge computing, manufacturers can achieve greater innovation, efficiency, and competitiveness. These technologies allow for real-time processing of unstructured data at the source, enabling more responsive and adaptive manufacturing systems. As the industrial landscape becomes increasingly complex and fast-paced, the ability to leverage unstructured data will be a critical factor in maintaining a competitive edge, making the shift from traditional Six Sigma methods to AI-enhanced Quality 4.0 not just beneficial but essential.
Binary classification of quality in manufacturing
Binary Classification of Quality (BCoQ) is a critical concept in modern manufacturing, particularly within the framework of Quality 4.0. In manufacturing, quality control is paramount to ensuring that products meet predetermined standards before they reach the customer. Traditionally, quality control relied heavily on human inspection and statistical methods applied to structured data. However, the Fourth Industrial Revolution has dramatically increased the complexity and volume of data generated in manufacturing environments. This shift has necessitated the adoption of more sophisticated methods, such as ML algorithms, to maintain and improve product quality.
How binary classification of quality works
Binary classification in quality control begins with the collection of data from various sensors, cameras, or other devices integrated into the manufacturing process. This data often includes features like temperature, pressure, humidity, and more abstract representations such as images or signals. Each sample of data is then labeled as either “good” or “defective” based on predefined criteria.
The labeled data is used to train a binary classification model, typically employing ML algorithms. These algorithms learn to identify patterns in the data that correspond to the two classes. For example, in a welding process, the power signal from a sensor might show distinct patterns when a weld is good versus when it is defective. The trained model can then predict the quality of new items based on real-time data, classifying each as either “good” or “defective.”
Importance and applications of BCoQ
The primary goal of BCoQ systems is to ensure that defective items are identified and addressed as early as possible in the manufacturing process. This is crucial for minimizing waste, reducing costs associated with rework or scrapping, and maintaining high customer satisfaction by preventing defective products from reaching the market.
In addition to defect detection, BCoQ systems can also be used for defect prediction. This proactive approach involves identifying patterns in the data that may indicate the potential for future defects, allowing for preventive measures such as equipment maintenance or process adjustments. This predictive capability is especially valuable in complex, high-speed manufacturing environments where the cost of downtime or product recalls can be substantial.
LQC systems
Learning Quality Control (LQC) is a type of CPS that uses IIoT, CSC, and AI technologies. These technologies are merged to develop real-time process monitoring and quality control systems. LQC systems can solve engineering problems that are difficult to solve using traditional QC methods.
LQC systems aim to predict and detect defects by identifying patterns of concern. Both tasks are framed as a binary classification problem. In Eqn (1), a positive label denotes a defective item, while a negative label represents a good-quality item. Since classification involves uncertainty, classifiers can make errors. In this context, a false positive (FP) occurs when the classifier triggers a false alarm to the monitoring system. A false negative (FN) arises when the classifier fails to detect the pattern of concern associated with a defective item. A true positive (TP) denotes the correct identification of the pattern of concern, while a true negative (TN) is when the monitoring system is not alerted correctly. These four elements are summarized in the confusion matrix:

Table 4: Confusion matrix. Prediction versus detection.
|
LQC can be applied to predict defects before they occur or detect them once they are generated.
- Defect prediction is a proactive process that involves detecting quality patterns early on to prevent potential quality issues. This can be achieved by scheduling maintenance, changing process parameters, or inspecting raw materials. Binary classification is used to identify fault patterns in process data, while the normal pattern is considered stable. If a fault pattern is detected (i.e., the classifier generates a positive outcome), it would trigger engineering efforts to correct the situation. However, since prediction is performed under uncertainty, there is a possibility of errors. A false positive requires no further action after troubleshooting. On the other hand, a false negative occurs when the classifier fails to detect a pattern of concern, resulting in defective items being generated downstream in the value-adding process.
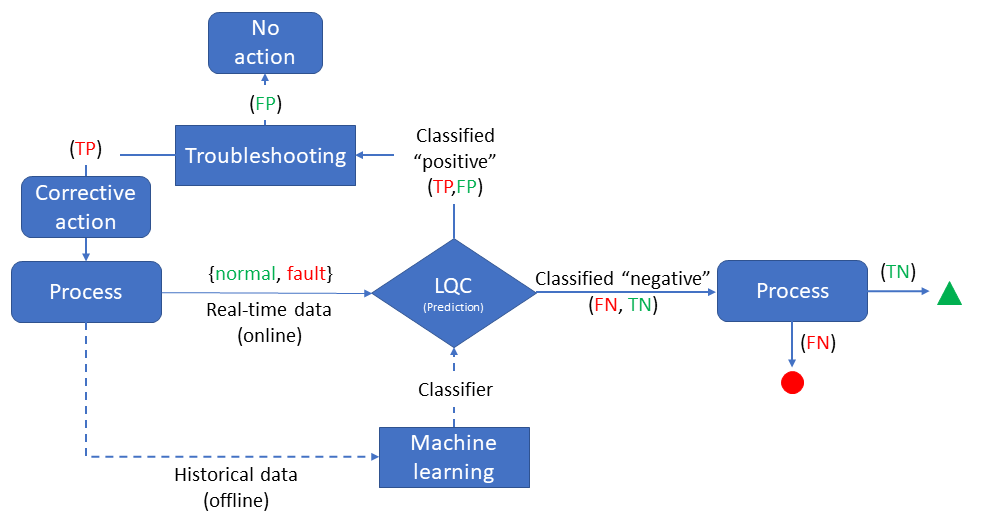
Figure 6: LQC for prediction application. Source: Escobar, Carlos A., and Ruben Morales-Menendez. Machine Learning in Manufacturing: Quality 4.0 and the Zero Defects Vision. Elsevier, 2024.
- Defect detection involves identifying defective items during a process. The process allows for the removal of manufactured defective items from the value-adding process. The defective items can either be reworked or scrapped. This helps to prevent warranty events or customer complaints. The FN (false negative) and FP (false positive) errors follow the same logic described in Fig. 6. The difference lies in the fact that in defect detection, the defects have already been generated. TP (true positive) items are either scrapped or reworked at the inspection station, while FP items may continue in the value-adding process after inspection. Finally, FN items become warranties or customer complaints.

Figure 7: LQC for detection application. Source: Escobar, Carlos A., and Ruben Morales-Menendez. Machine Learning in Manufacturing: Quality 4.0 and the Zero Defects Vision. Elsevier, 2024.
In Figs. 6 and 7, it is shown that FN errors can result in defects, warranty events, or customer complaints, while FP errors can cause inefficiencies due to scrap and rework, also known as the hidden factory effect. Although both types of errors are important in manufacturing, FN errors are particularly significant. Therefore, the primary objective of LQC is to create a classifier that can detect nearly 100 % of the defective items (β ≈ 0) while only committing a few FP errors. Two illustrative case studies using structured and unstructured data are presented in my previous article.
5-step problem solving strategy for AI innovation
The proposed five-step problem-solving strategy for LQC systems, Figure 8, in the context of Quality 4.0 is as follows:
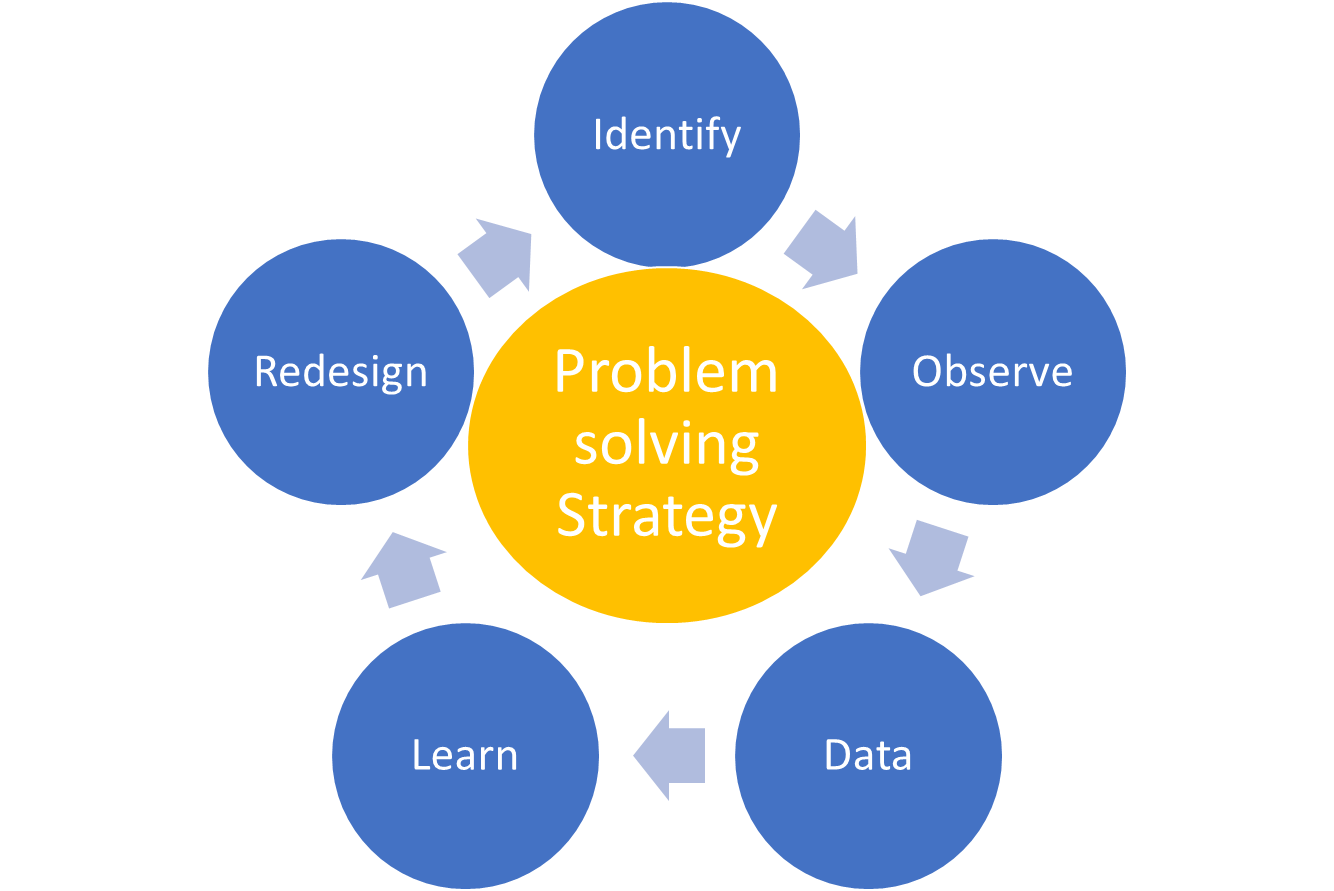
Figure 8. Problem solving strategy for LQC systems. Source: Escobar, Carlos A., and Ruben Morales-Menendez. Machine Learning in Manufacturing: Quality 4.0 and the Zero Defects Vision. Elsevier, 2024.
- Identify
The first step focuses on selecting the right problem and defining the learning targets and expected benefits. This is crucial as many AI projects fail due to improper project selection. The selection process involves deep technical discussions and business value analysis to develop a prioritized portfolio of projects. This step ensures that the selected project aligns with the overall strategy and has the necessary data and feasibility to succeed.
- Observe
This step is about determining the devices and communication protocols that will be used to generate the necessary data. In Industry 4.0, this often involves integrating sensors and IoT devices into manufacturing processes to collect real-time data. The step requires a combination of process domain knowledge and communication engineering to effectively monitor the system.
- Data
Once the data generation devices are in place, the next step is to generate and preprocess the learning data. This involves creating features, signals, or images and labeling each sample appropriately. The quality of the data is critical as it forms the foundation for the ML algorithms that will be developed in the next step.
- Learn
Relearning is essential in maintaining the predictive accuracy of ML models used in quality control as they encounter new data patterns over time. As manufacturing processes evolve, the statistical properties of the data—such as distributions of classes—can drift, leading to a degradation in the performance of initially trained models.
Figure 9 illustrates the comparison between a deployed solution with and without a relearning strategy. Without relearning, the model’s performance degrades significantly over time as the process changes. However, with a relearning strategy, the model continuously adapts, maintaining its prediction accuracy and compliance with the plant’s requirements.

Figure 9: Relearning vs no relearning strategy. Source: Escobar, Carlos A., and Ruben Morales-Menendez. Machine Learning in Manufacturing: Quality 4.0 and the Zero Defects Vision. Elsevier, 2024.
The relearning step ensures that models remain effective by continuously adapting to these new variations.
The process involves:
- Learning strategy: Developing a comprehensive plan that includes data generation, model training, hyperparameter tuning, and validation. The outcome is a model that meets predefined performance goals on unseen data.
- Relearning data set: Using true positives and false positives observed in the inspection stations to update the model. This step ensures the model continuously learns the statistical properties of both good and defective items.
- Relearning schedule: Retraining the model frequently, based on the dynamics of the manufacturing plant, to adapt quickly to new sources of variation. This can be scheduled daily or weekly, depending on the process requirements.
- Monitoring system: Implementing an alerting mechanism to monitor the model’s performance. If the model starts losing accuracy, temporary measures such as manual inspections or random sampling can be initiated to maintain quality control while the model is retrained.
- Redesign
Redesign focuses on leveraging the insights gained from the data-driven analyses and ML models to guide long-term process improvements. While the relearning step is primarily concerned with real-time adjustments, redesign is an offline activity aimed at preventing defects by redesigning the process itself.
This step involves:
- Engineering knowledge discovery: Using the results from data mining and ML to generate hypotheses about the underlying causes of quality issues. This can include identifying connections between specific features and product quality.
- Root-cause analysis: Conducting detailed analyses to uncover the root causes of defects, supported by statistical methods and engineering principles.
- Process redesign: Implementing changes in the manufacturing process based on the insights gained. The goal is to eliminate defects from a physics perspective, ensuring that the process is fundamentally improved and that quality issues are less likely to occur.
Figure 10 shows how the redesign process is informed by the data-driven insights from previous steps. The redesign step results in a process that is better aligned with the physical realities of manufacturing, thus preventing defects and improving overall quality.
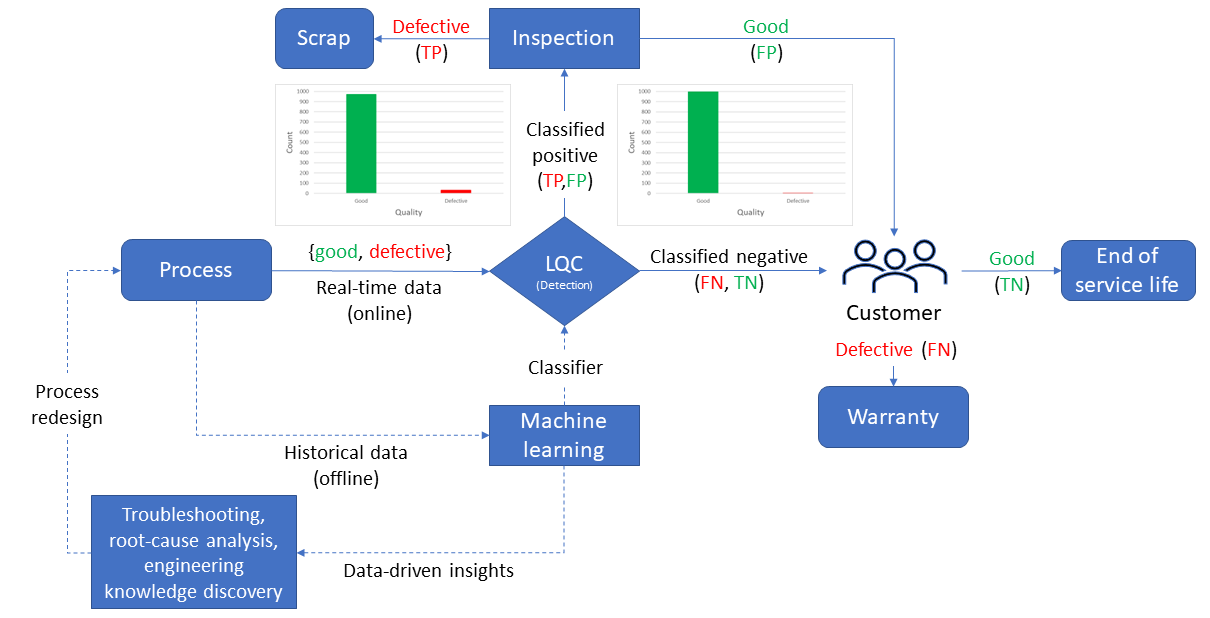
Figure 10: Process redesign. Source: Escobar, Carlos A., and Ruben Morales-Menendez. Machine Learning in Manufacturing: Quality 4.0 and the Zero Defects Vision. Elsevier, 2024.
This five-step strategy integrates advanced AI techniques and modern infrastructure to enhance traditional quality control methods, making them more adaptable and effective in the complex environments of modern manufacturing.
Concluding remarks
The rapid advancements of the Fourth Industrial Revolution have fundamentally transformed manufacturing, introducing unprecedented complexities and vast amounts of unstructured data. Traditional quality management methodologies, such as Six Sigma’s DMAIC, while effective in more stable, structured environments, are increasingly inadequate for addressing the dynamic and data-intensive challenges of modern manufacturing.
Quality 4.0, with its integration of AI, IIoT, and advanced data management technologies, offers a robust framework for overcoming these challenges. The Learning Quality Control (LQC) systems proposed in this article exemplify how AI-driven approaches can revolutionize quality management, enabling real-time data analysis, continuous learning, and adaptive process control. The five-step problem-solving strategy—Identify, Observe, Data, Learn, and Redesign—provides a practical roadmap for implementing these systems, ensuring that they are both effective and adaptable to the rapidly evolving manufacturing landscape.
As industries continue to embrace these new technologies, transitioning from traditional methodologies to AI-driven solutions will be essential for sustaining competitiveness and fostering innovation. Embracing Quality 4.0 is not just a strategic advantage but a necessity for thriving in today’s complex, fast-paced industrial environment. For a comprehensive understanding of the LQC systems paradigm, I invite you to explore my book, “Machine Learning in Manufacturing: Quality 4.0 and the Zero Defects Vision.”
READ MORE FROM THE AUTHOR
Looking for a reprint of this article?
From high-res PDFs to custom plaques, order your copy today!






